1. SURVEYING:
It is the art of determining the relative position of points on the earth’s surface by measuring
the horizontal between them. Levelling is the process of determining the position of points in
a vertical plane
Surveying are of two types
1) Geodetic survey: the survey in which the shape of the earth is taken in to account is called
geodetic surveying
2) Plane survey: the survey in which the shape (or) curvature of earth is not taken in to account
is called plane surveying
The scope of surveying and levelling are:
a) To prepare plan and map which help in project implementation (setting out the alignment
for a road or railway track or canal, deciding the location for a dam or airport or harbour)
b) To determine the dimensions and contours of any part of the earth surface
c) To establish boundaries of land
d) To measure the areas and volume of land
e) To select suitable site for an engineering project
f) To conduct engineering survey, topographical survey, military survey, mine survey,
geological survey, archaeological survey, hydro graphic survey, environmental survey etc..
The Knowledge of surveying is essential in many phases for every engineering project such as
buildings, roadways, railways, dams, bridges, tunnels, harbours, mines, water supply and
sanitation, pipe line laying, airports etc..
2. BUILDING MATERIALS:
Any engineering structure requires a wide range of materials known as building materials. The
building materials chosen should have such properties that are safe, economical, eco-friendly
and serviceable for the purpose for which they are used
The building materials can be broadly divided into following categories
a. Traditional materials: stones, timber, bricks, lime, cement, tar, bitumen, mortar, ferrous
and non-ferrous metals etc
b. Alternative building materials: mud blocks, concrete blocks, glass, aluminium, paint,
flyash etc.
c. Composite materials: RCC, fibre reinforced concrete, ferro-cement, composite laminated
doors, asbestos sheets, fibre reinforced glass etc.
3. CONSTRUCTION TECHNOLOGY:
As land cost is going up there is a demand for tall structures in urban areas, while in rural areas
need for low cost construction, one has to develop technology using locally available materials
Construction technology comprises of different techniques of construction for different
materials under site different condition. The study of construction machinery comes under its
purview. The management or organization of men (labour), material, method in relation to site,
money and time is the backbone of construction management. It involves almost every branch
of engineering, commerce and economics, for; its ultimate aim is to ‘achieve the desired
construction in the most economical way. A clear knowledge of following points is necessary
for reliable construction and its management.
a) Money, Materials, Machines, Manpower, Methodologies,
b) Maintenance, Modernization, Monitoring, Motivations,
c) Managements of all types.
4. GEO-TECHNICALENGINEERING (Soil Mechanics):
The load from the structure is to be safely transferred to soil, for this safe bearing capacity of
soil is to be properly assessed. This branch of study in civil engineering is called geotechnical
engineering, which deals with the study of the properties , behaviour and use of earth materials
(soil and rocks) in engineering works
Geotechnical engineering has much wider scope that:
a) It is concerned with the properties of earth materials
b) To investigate the soil and bed rocks below the structure and study the soil structure
interaction
c) To select the type of foundation earth works for particular structure
d) To design foundation of building, dams, retaining walls, bridges, road pavement, railway
lines etc.
e) To design foundation for underground structure like tunnels, power houses etc.
f) To design foundation for machines such as turbines, compressors etc. to transmit vibrations
to foundation soil
g) To study the effect of soil as a medium for blasts during mining, earthquake, landslides and
nuclear explosionsh) They include various types of foundations like shallow foundation, deep foundations. Pile
foundation, well foundation etc.
5. STRUCTURAL ENGINEERING :
A building or a bridge or a dam consists of various elements like foundations, columns, beams,
slabs etc. These components are always subjected to forces. Depending upon the materials
available the components of the building should be safely and economically designed. A
structural engineer is involved in such a designing activity
Scope of structural engineering:
a) The structural engineering plays a vital role in planning, designing and building the structure
b) The structural analysis and structural design are the components of structural engineering
c) The structural engineering should take the responsibility about the safety and serviceability
of the structure for its life time
d) The structural engineer should be prepared for to accept the natural calamities like
earthquake, wind, landslide etc. and provide remedial measures
6. HYDRAULICS ENGINEERING :
Water is an important need for all living beings, study of mechanics of water and its flow
characteristics is another important field in civil engineering and its known as hydraulics
Hydraulics mainly deals with the practical problems of flow of water. The concept of fluid
pressure, fluid statics, and flow pattern helps in engineering to design the structures like dams,
reservoirs, bridges, culverts, sewage system etc. this concept is also used for flow through
pipes, pumps, turbines, hydraulic machines etc. Hydroelectric power generation facilities are
also included under this aspect.
7. WATER RESOURCES AND IRRIGATION ENGINEERING :
Water is to be supplied to agricultural fields and for drinking purposes, hence suitable water
resources are to be identified and water is to be stored. Identifying, planning and building water
retaining structures like tanks and dams and carrying stored water to agricultural fields through
irrigation channels is known as water resources and irrigation engineering
Scope of water resources and irrigation engineering:
a) It facilitates to control, regulate and utilize water to serve wide variety of purposes
b) It gives scope for utilization of water in beneficial purpose by providing water supply,
irrigation, hydroelectric power development and navigational improvement
c) Water quality management
d) Scope for recreational use of water resourcese) To protect fish and wild life
f) India being an agricultural country, irrigation will definitely help in the overall development
of our country, citizen and improve the civilization
8. TRANSPORTATION ENGINEERING:
Transportation means the movement of the men and goods from one point to another. It is as
old as civilization
The Transportation system includes road ways, railways, airways and water ways, design,
construction and maintenance of railway lines, signal system are part of the transportation
engineering.
Scope of water resources and transportation engineering:
a) It contributes to the economic, industrial. Social and cultural development of any country
b) To optimise the transportation cost, maintenance and administrative overheads
c) Planning the transport process with respect to survey and analysis of existing condition and
forecasting the future condition
d) It involves accident study for safe and comfort transport system
e) For traffic performance and control
9. ENVIRONMENTAL ENGINEERING :
People in every village, town & city need potable water. The water available (surface water &
ground water) may not be fit for direct consumption. In such cases, the water should be purified
and then supplied to the public. For water purification, sedimentation tanks, filter beds, etc.
should be designed. If the treatment plants are for away from the town or city, suitable pipelines
for conveying water & distributing it should also be designed.
In a town or city, a part of the water supplied returns as sewage. This sewage should be
systematically collected and then disposed into the natural environment after providing suitable
treatment. The solid waste that is generated in a town or locality should be systematically
collected and disposed of suitably. Before disposal, segregation of materials should be done so
that any material can be recycled & we can conserve our natural resources.
Scope of environmental engineering:
a) The study of importance of protection and conservation of our environment
b) The proper distribution of water supply with water treatment facility
c) Solution of problems of environment sanitation with waste water treatmentd) The proper disposal of / recycle of waste water and solid waste
e) Adequate drainage of urban, rural and recreational areas
f) Control of air pollution and provide healthy environment to public

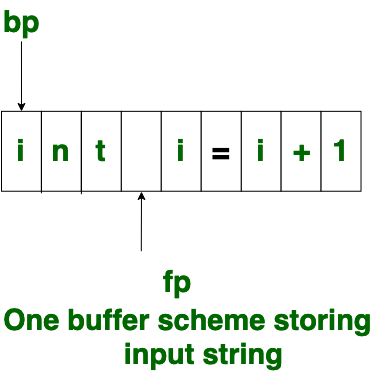
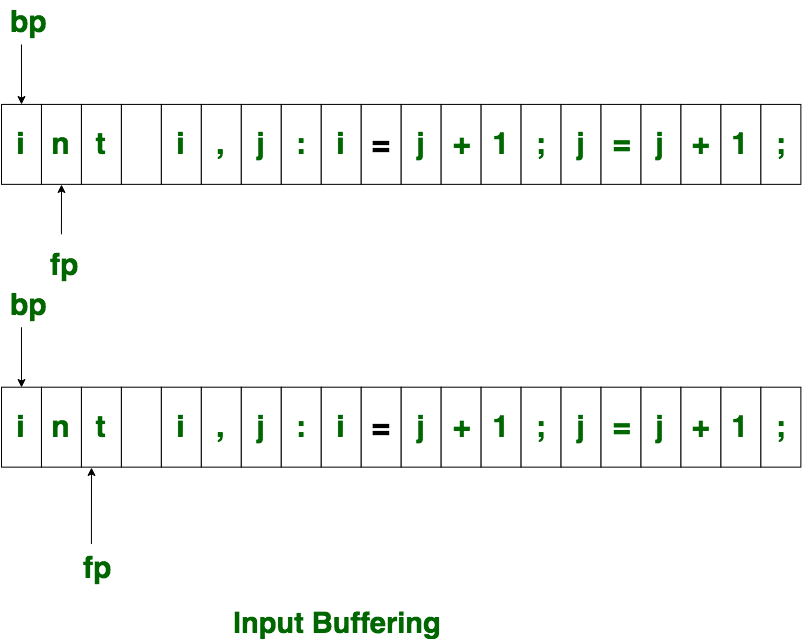 The forward ptr moves ahead to search for end of lexeme. As soon as the blank space is encountered, it indicates end of lexeme. In above example as soon as ptr (fp) encounters a blank space the lexeme “int” is identified.
The fp will be moved ahead at white space, when fp encounters white space, it ignore and moves ahead. then both the begin ptr(bp) and forward ptr(fp) are set at next token.
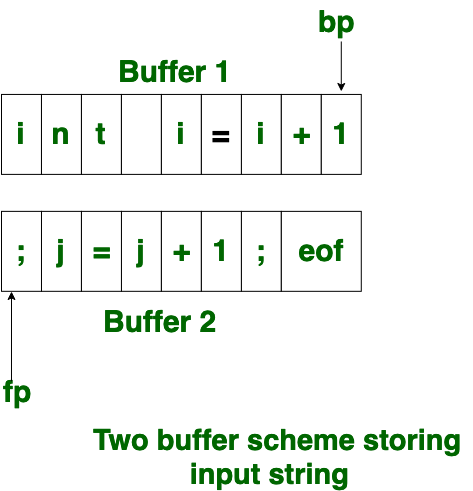
The input character is thus read from secondary storage, but reading in this way from secondary storage is costly. hence buffering technique is used.A block of data is first read into a buffer, and then second by lexical analyzer. there are two methods used in this context: One Buffer Scheme, and Two Buffer Scheme. These are explained as following below.
The forward ptr moves ahead to search for end of lexeme. As soon as the blank space is encountered, it indicates end of lexeme. In above example as soon as ptr (fp) encounters a blank space the lexeme “int” is identified.
The fp will be moved ahead at white space, when fp encounters white space, it ignore and moves ahead. then both the begin ptr(bp) and forward ptr(fp) are set at next token.
The input character is thus read from secondary storage, but reading in this way from secondary storage is costly. hence buffering technique is used.A block of data is first read into a buffer, and then second by lexical analyzer. there are two methods used in this context: One Buffer Scheme, and Two Buffer Scheme. These are explained as following below.